
How to connect with PostgreSQL-
sudo -i -u postgres


Grant the necessary privileges for the new user to connect to your
database:
Grant connect on database exampledb to user name;
Grant usage on schema public to user name;

How to Connect with PSQL Shell-
Psql

How to select version of PostgreSQL and Current Date-
Select Version ();

How to create Database in PostgreSQL –
Create database Employee;

How to Connect with Specific database in PostgreSQL-
\c database_name;

How many database are present in PostgreSQL Server-
\l+

How many tables are there in the PostgreSQL database-
\dt+

Create Table statement-
Create table empdetails (Id int primary key, Name (Text), Age (int), Address char (50), Salary (real));

Insert data in the Table-
Insert into empdetails (Id, Name, Age, Address, Salary) values (1, ‘Abhishek’, ‘25’, ‘LKO’ M ‘25000’);

Select Data from the Table-
Select * from empdetails;

Counting Rows statement-
Select count (*) from empdetails;

Structure table statement-
\d empdetails;

List all stored procedures and functions-
\df+ or \df


Create user statement in PostgreSQL –
CREATE ROLE username Abhi LOGIN PASSWORD ‘secure@321’;

Change role for the current session to the new_role-
SET ROLE Abhi;

If you want to give all privileges to a newly created user, execute the following command-
GRANT ALL previleges
ON table_name
TO role_name;

Check Table Privileges Using “\z” Command-
\z emp_info;

Drop user statement-
DROP USER ‘account_name’;

Revoke Statement-
Revoke all privileages on table name from user name;

Show Users in PostgreSQL
\du;

To log in without a password:
Psql –d dbname -u username

Change PostgreSQL User Password Statement-
ALTER USER user_name WITH PASSWORD ‘new_password’;
PostgreSQL ALTER Table-
ADD a column in the table-
ALTER TABLE table_name
ADD COLUMN column_name datatype column_constraint;

Alter column in the table-
ALTER TABLE table_name
Alter column_name column_definition
[ FIRST | AFTER column_name ];

DROP column in table-
ALTER TABLE table_name
DROP COLUMN column_name;

RENAME column in table-
ALTER TABLE table_name
RENAME COLUMN column_name
TO new_column_name;

RENAME table-
ALTER TABLE table_name
RENAME TO new_table_name;

Create Stored Procedure Syntax-
CREATE OR REPLACE FUNCTION my_stored_procedure()
LANGUAGE plpgsql;
AS
$$
BEGIN
— Your procedure logic goes here
— You can write SQL statements, control structures, etc.
— For example:
RAISE NOTICE ‘Hello, World!’;
END;
$$
Let’s break down the above example:
CREATE OR REPLACE FUNCTION: This is the statement to create a function or stored procedure in PostgreSQL. The OR REPLACE option allows you to modify the function if it already exists with the same name.
my_stored_procedure(): This is the name of the stored procedure. You can give it any name you prefer.
$$: This is the dollar-quoted string syntax that encloses the body of the stored procedure.
BEGIN and END: These keywords define the beginning and end of the procedure block, where you can write your procedure logic.
RAISE NOTICE ‘Hello, World!’;: This is an example of a statement inside the procedure. It raises a notice message that will be displayed when the procedure is executed.
LANGUAGE plpgsql;: This specifies the language used for the stored procedure. In this case, it’s “plpgsql,” which is the procedural language for PostgreSQL.

Create function in PostgreSQL Statement-
CREATE OR REPLACE FUNCTION get_total_rows(table_name text)
RETURNS bigint AS
$$
DECLARE
total_rows bigint;
BEGIN
EXECUTE format(‘SELECT COUNT(*) FROM %I’, table_name) INTO total_rows;
RETURN total_rows;
END;
$$
LANGUAGE plpgsql;

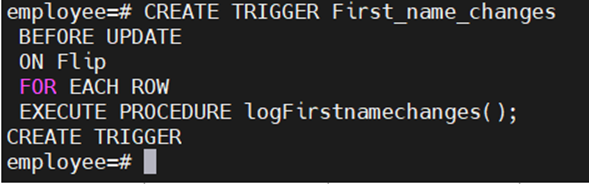
Create Trigger Statement-
CREATE TRIGGER trigger_name
{BEFORE | AFTER} { event }
ON table_name
[FOR [EACH] { ROW | STATEMENT }]
EXECUTE PROCEDURE trigger_function

List sessions / active connections in PostgreSQL database-
select pid as process_id,
usename as username,
datname as database_name,
client_addr as client_address,
application_name,
backend_start,
state,
state_change
from pg_stat_activity;
- process_id – process ID of this backend
- username – name of the user logged into this backend
- database_name – name of the database this backend is connected to
- client_address – IP address of the client connected to this backend
- application_name – name of the application that is connected to this backend
- backend_start – time when this process was started. For client backends, this is the time the client connected to the server.
- State – current overall state of this backend. Possible values are:
o active
o idle
o idle in transaction
o idle in transaction (aborted)
o fastpath function call
o disabled
- state change – time when the state was last changed

Finding blocked processes and blocking queries-
SELECT
activity.pid,
activity.usename,
activity.query,
blocking.pid AS blocking_id,
blocking.query AS blocking_query
FROM pg_stat_activity AS activity
JOIN pg_stat_activity AS blocking ON blocking.pid = ANY(pg_blocking_pids(activity.pid));

Index Statement-
CREATE INDEX index_name ON table_name;
Single-Column Indexes-
CREATE INDEX index_name
ON table_name (column_name);
Multicolumn Indexes-
CREATE INDEX index_name
ON table_name (column1_name, column2_name);


Drop Primary Key-
ALTER TABLE table_name
DROP CONSTRAINT constraint_name;

PostgreSQL REINDEX syntax-
REINDEX
[ ( VERBOSE ) ]
[ ( CONCURRENTLY [ boolean ] ) ]
[ ( TABLESPACE new_tablespace ) ]
{ INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } name;
Explanation:
- The VERBOSE keyword is not required. If this keyword is specified, progress will be shown while the index is rebuilt.
- The keyword CONCURRENTLY is optional. PostgreSQL will not halt any table operations while the index is rebuilt with it.
- TABLESPACE new_tablespace is not required. PostgreSQL will use it to rebuild indexes on the new tablespace.
- The index object to rebuild is specified by the term INDEX | TABLE | SCHEMA | DATABASE | SYSTEM.
· REBUILD INDEX: Recreate the provided index.
· TABLE: This command rebuilds all indexes in the chosen table.
· SCHEMA: Rebuild all indexes in the schema supplied.
· DATABASE: In the specified database, rebuild all indexes.
· SYSTEM: Rebuild all indexes in the chosen database’s system catalogue.
· The name specifies the object’s name.
Here are some examples of specific applications:
Use the INDEX keyword and the index name to recreate a single index:
REINDEX INDEX index_name;
To rebuild all indexes in a table, use the TABLE keyword with the table name:
TABLE REINDEX table_name;
To rebuild all indexes in a schema, use the SCHEMA keyword and the schema name:
REINDEX SCHEMA schema_name;
Use the DATABASE keyword and the database name to rebuild all indexes in a database:
REINDEX DATABASE database_name;
Use the SYSTEM keyword and the database name to rebuild all indexes on the system catalogue in one data:
REINDEX SYSTEM database_name;
Exit psql shell-
\q

Leave a Reply